La Scheda Video

DISCLAIMER
This Work: “Consigli per l’acquisto di RAM per Ryzen gen. 1 2 e 3 (Update 2019)” by R3d3x is licensed under CC BY-NC-SA 4.0.
Quest’opera è stata rilasciata con licenza Creative Commons Attribuzione – Non commerciale – Condividi allo stesso modo 4.0 Internazionale.
L’AUTORE DELLA GUIDA ORIGINALE è R3d3x, moderatore del forum HWreload.
Io ho solamente riportato la guida modificandola parzialmente, semplificandola, rendendola più semplice per i lettori e aggiungendo contenuti parziali rispetto la guida originaria.
Al seguente link troverete la guida originaria, sempre aggiornata con maggiori dettagli inseriti e indicati dall’autore R3d3x.
Vi consiglio di seguire il suo canale tech su YouTube, nello scenario della tecnologia, per le enormi competenze, serietà ed obiettività, a mio modesto parere, è fra i migliori in assoluto.
Un ringraziamento particolare va all’autore di questa guida che mi ha concesso la possibilità di poter divulgare il suo enorme lavoro, non smetterò mai di ringraziarti R3d3x!
Al seguente video troverete una breve spiegazione tecnica che mostra la composizione di una Scheda Video (GPU).
Livello di Conoscenza base della GPU
GPU è l’acronimo inglese per Graphics Processing Unit tradotto è Unità di Elaborazione Grafica.
La GPU è il nucleo delle schede video, definito anche come processore grafico o coprocessore.
La sua funzione è il rendering (dall’inglese interpretazione/traduzione/esecuzione) delle immagini grafiche che noi rivediamo sullo schermo.
La Graphics Card o Video Card contiene quasi un altro PC al suo interno quindi la GPU, la memoria, e tanto altro utile ai fini dell’elaborazione, dell’alimentazione della stessa e al suo raffreddamento.
Il programma più adatto per guardare tutte le specifiche della nostra scheda video è GPU-Z, un must have tra i propri programmi come per CPU-Z.
Schede Video Dedicate ed Integrate
Esistono schede video dedicate ovvero una scheda fisica che va aggiunta al PC in collegamento tramite gli slot PCIe e schede video integrate sul package del processore.
Quest’ultime sono conosciute come iGPU (acronimo di integrated GPU) vanno menzionate soprattutto le Intel Graphics e le APU (acronimo per Accelerated Processing Unit) di AMD.
Due delle più potenti APU sono utilizzate sulle console come ad esempio la PS4 Pro (APU Jaguar Neo) e Xbox One X (APU Jaguar Scorpio).
Infine abbiamo anche delle soluzioni doppie con un rapido switch automatico da una soluzione ad un’altra come nel caso dei notebook.
Opzione che può essere resa manuale tramite il BIOS (passando quindi da un’opzione dinamica ad una fissa).
In questo caso si passa dall’utilizzo della iGPU per applicativi leggeri, all’utilizzo della scheda video dedicata e saldata alla piastra madre per applicativi più pesanti come rendering, gaming etc.
Competitor, scopi delle GPU e famiglie
Attualmente i maggiori competitor in GPU sono: NVIDIA Corporation, AMD (Advanced Micro Devices) ed Intel.
Prima ne esistevano molti di più, ma sono stati schiacciati dalla concorrenza non riuscendo a tenere il passo.
Alcune sono fallite, altre hanno semplicemente abbandonato questa lotta pur rimanendo nello stesso campo.
Ricordiamo tra queste: ATI (acquisita da AMD nel 2006), Matrox (ancora oggi, sviluppa schede video professionali e non più da gaming), 3dfx (famose sono le Voodoo, le prime GPU accelerate 3D e inventori del primo SLI, che fu assorbita da NVIDIA nel 2001), SIS, VIA, etc.
Le GPU hanno principalmente 3 scopi oltre quello base di mandare a video le informazioni della CPU: Gaming, Editing e General-Purpose (GPGPU).
Le GPGPU non hanno uscite video come le restanti, poiché si prestano ad altri scopi.
Vengono utilizzate per l’esecuzione di calcoli paralleli particolarmente complessi come:
- criptovalute (mining)
- matematica e sicurezza (crittografia)
- fisica (meccanica quantistica)
- chimica e biologia (modellazione proteica)
- astronomia e astrofisica (decodifica segnali spaziali)
- calcolo distribuito (BIONIC) etc.
NVIDIA: GeForce per Gaming, Quadro per Editing e Tesla per General Purpose.
AMD: RX Vega per uso base integrate nelle APU, Radeon per Gaming e Radeon Pro (in precedenza FirePro) per Editing e FireStream per General Purpose.
Intel: Intel Graphics per uso base integrate nei processori Intel e Xeon Phi per General Purpose.
Curiosità
Le Adreno (GPU smartphone con SoC Qualcomm) furono inizialmente sviluppate da ATI.
Quest’ultime erano chiamate con il nome Imageon, questo prima del 2006 con l’acquisizione da parte di AMD.
Nel 2009 dopo che AMD vendette la divisione, Qualcomm decise di rinominare queste GPU con l’anagramma della parola Radeon, ovvero Adreno.
Schede Video Reference e Schede Video Custom sviluppate dai Partner
AMD e NVIDIA sono gli ideatori delle GPU attuali.
Aziende di schede video dedicate che si fanno produrre i chip da aziende esterne per poi introdurli nelle loro schede video.
Tali schede sono definite come Schede Video Reference (dall’inglese riferimento).
Questo significa che sono il punto di riferimento per ogni altra scheda con la stessa GPU sviluppata dalle aziende.
In genere i prodotti reference non sono la prima scelta dei consumatori.
Sebbene siano potenzialmente allo stesso livello di tutte le altre GPU, possiedono molte possibilità di miglioramento in determinati ambiti della scheda video.
Da qui sono nati dei partner che vendono le schede video customizzate ovvero personalizzate.
Quest’ultimi acquistano le GPU da NVIDIA e AMD e che apportano modifiche all’intera scheda video definita quindi Custom.
Queste modifiche possono essere al sistema di dissipazione (heatsink, ventole, etc.), al PCB (acronimo per Printed Circuit Board, tradotto in circuito stampato).
Questo implica dimensioni ITX o dimensioni schede video più lunghe per adattarci sopra magari un dissipatore con 3 ventole invece che con 2.
Possono modificare la parte dei VRM aumentandoli o modificare il BIOS o apportare revisioni.
Possono acquistare chip binned per modificare al massimo la frequenza della GPU e rivenderle come versioni overclockate rispetto ad altri chip con frequenze più basse.
Molte volte la differenza è quella estetica, anche perché il chip della GPU è sempre lo stesso.
Questo si traduce in genere in performance simili sotto il profilo della resa in fps.
La differenza tra quelle overclockate o di fabbrica spesso è di pochi fps, con un esborso che non vale la differenza di prezzo.
La differenza di binning, di raffreddamento, di VRM e PCB non giustifica quella differenza di prezzo, figuriamoci gli RGB.
Aneddoto realmente successo
Questo non è sempre vero e non è sempre falso, ogni custom va comunque valutata da un recensore esperto che abbia a sua disposizione gli strumenti per poterla recensire.
In passato è accaduto che alcune schede video di una blasonata marca X, spesso nominate per l’ottimo sistema di raffreddamento, avessero una così pessima dissipazione dei VRM tale da causare thermal throttling.
N.B.: è il sistema di protezione della scheda quando supera la temperatura critica, quest’ultima si spegne e le frequenze si arrestano per evitare danni al chip nei momenti di maggior picco.
Situazione che si ripeteva puntualmente con la medesima custom a tantissimi utenti che l’hanno acquistata.
Questo aneddoto è per far capire quanto sia importante ed essenziale, prima di valutare una qualsiasi custom di qualsiasi marca, leggere le review fatte da esperti.
Partner NVIDIA
MSI, ASUS, Gigabyte, GALAX (chiamata KFA2 in Europa e Kurotoshikou nel mercato Asiatico), Palit, Gainward (acquisita da Palit), EVGA, Zotac, Inno3D, PNY, Manli, Yeston, Colorful, Maxsun, Biostar, ed altri come Point of View, ASL, Atum, AXLE, ELSA, EMTEK, Geekstar, Leadtek, SNKTech, Alienware.
Partner AMD
MSI, ASUS, Gigabyte, Sapphire, XFX, Powercolor, ASRock, HIS, Yeston, Biostar, Kurotoshikou (ovvero Galax nel mercato asiatico), Maxsun, ed altri come Arez, ColorFire, Dataland, Onda, PCYES, Pradreon, VisionTek.
Raramente qui in Italia, ma soprattutto nei forum esteri o parlando con tecnici di aziende, ci si può riferire a questi partner come AIB suppliers (acronimo di Add in Board tradotto aggiungere alla scheda, suppliers tradotto come fornitore).
Per essere precisi chiunque aggiunga o faccia modifiche su di un qualsiasi tipo di scheda come ad esempio G.Skill che modifica le memorie vendute da SK Hynix o Samsung (definito come manufacturer o produttore), può essere definito AIB suppliers, la scheda viene invece definita AIB o Custom.
Quindi non solo i partner che modificano le schede video, ma qualsiasi partner che modifica qualsiasi scheda può essere correttamente definito AIB suppliers.
Componenti di una scheda video
Qui vediamo l’intera scheda video scoperchiata (spesso chiamata barebone) dall’heatsink, dalle ventole e dallo chassis. Possiamo quindi vedere tutti i componenti interni della scheda video saldati al PCB (Circuito Stampato).

Printed Circuit Board

Il PCB, acronimo di Printed Circuit Board, non è altro che l’unione di vari layer (strati o livelli).
Può essere composto da materiale posti a più livelli, per questo anche detto Multi-Layer PCB.
Riassumendo vi sono un top layer e un bottom layer ovvero uno strato superficiale superiore e uno strato superficiale inferiore.
Quelli che riusciamo a vedere solitamente; le piste che vedete sulla scheda madre che si diramano all’interno del PCB vengono chiamate PCB Tracks.
La lunghezza fisica della scheda video è decisa dai partner in base alle modifiche scelte per il PCB.
Esistono GPU lunghe ben oltre i 300mm o, viceversa, schede di dimensioni più compatte definite solitamente in formato ITX.
Quest’ultime sono compatibili con case di piccole dimensioni in genere in form factor mATX o ITX.
Questa tipologia di schede video hanno caratteristiche tecniche inferiori, considerando il form factor:
- Dissipatore più piccolo con un’unica ventola (minor capacità di raffreddamento = Temperature più alte)
- Minor numero di VRM (overclock meno spinto e stabile)
- Meno uscite video
Prima di cambiare case o scheda video assicuratevi quindi della lunghezza che il case può supportare.
In genere indicato nelle specifiche del case come Maximum GPU Length, ovvero la lunghezza massima delle schede video supportate.
Viceversa quando cambiare scheda video assicuratevi che la lunghezza supportata dal case sia compatibile con la lunghezza della nuova scheda video.
Le schede video con PCB identico a quello delle schede video Reference ma con altre modifiche come sulla frequenza del processore o sul dissipatore, vengono chiamate Semi-Custom; se viene fatta una modifica anche al PCB, non si tratta più di reference o una semi-custom ma di una vera e propria Custom.
Graphic Processor Unit

La GPU (acronimo di Graphic Processor Unit tradotto come Unità di Elaborazione Grafica) viene definita anche come coprocessore o processore grafico.
Naturalmente funziona quindi come un vero e proprio processore con una sua frequenza, con voltaggi e tensioni che si applicano.
A differenza della CPU che possiede un ALU (acronimo per arithmetic-logic unit o unità aritmetica-logica), la GPU è dotata di molti più calcolatori.
La CPU nasce per processare le istruzioni ed è basata su di un sistema chiamato MIMD (multiple instruction, multiple data) potendo svolgere più istruzioni; la GPU nasce per effettuare dei calcoli, motivo per il quale essa è basata su un sistema chiamato SIMD (Single istruction, multiple data).
Quindi nonostante possa eseguire un’unica istruzione per volta, riesce a farlo con una tecnica di parallelizzazione del lavoro impressionante, il che comporta a sua volta un impressionante capacità di calcolo.
Valori fondamentali della GPU

La GPU ha 3 fondamentali valori che migliorano di anno in anno in base all’affinamento delle fabbriche, e allo sviluppo delle architetture ovvero:
- La dimensione del Die, (in inglese Die Size) misurabile in mm².
- Il numero di transistors, in genere nell’ordine dei 10-20 mila milioni. Qui ritroviamo la famosa legge di Moore, ovvero che: “Il numero di transistor raddoppia ogni due anni.”
- Il processo costruttivo (in inglese Process Size o Technology) esprime la lunghezza del gate (ovvero la distanza tra drain e source nei transistors) misurabile in nanometri (7nm, 10nm, 12nm, 14nm, 16nm, 28nm, 32nm etc.)
Processo produttivo

Un esempio si può fare sul processo produttivo usato dalle GPU NVIDIA Turing di 12nm e 7nm per le GPU AMD (Radeon VII).
Questo processo produttivo indica la dimensione minima del gate di ogni singolo transistor.
Per renderci conto della dimensione della quale parliamo, vi faccio un paragone: un globulo rosso è mediamente 7000nm, mentre il virus dell’HIV (quello che causa l’AIDS) è di 120nm ovvero 100 volte più grande del gate dei transistor.
I vantaggi nel passare ad un processo costruttivo più piccolo, in generale è cercare di migliorare sempre più la miniaturizzazione.
I motivi sono molteplici, si va dal miglioramento della resa produttiva con conseguente abbattimento di costi (più un processore è “piccolo” e più GPU possono essere fabbricate con un solo wafer), alla diminuzione del consumo elettrico e della temperatura operativo.
Oppure con le stesse dimensioni vi è la possibilità di integrare un numero di transistor sempre maggiore con conseguente aumento della potenza elaborativa, senza però l’aumento della dissipazione di calore.
Anche se il processore produttivo è tecnicamente solo un numero senza un reale valore, questo poiché non è l’unica dimensione che va calcolata, inoltre non identifica la reale densità di transistor.
Circuito integrato
Il Die è traducibile in italiano come circuito integrato o stampo, ovvero un piccolo blocco posto all’interno del package (l’involucro esterno della GPU).
La dimensione del Circuito integrato (Die Size) può aumentare in base alla quantità di transistor che utilizza, ma non è detto che se ha un processo produttivo a 7nm sia di dimensioni più piccole rispetto ad uno di 14nm, anzi, in genere è più grande per ospitare più transistor possibili.

Il transistor
Il nome deriva dalle parole inglesi transconductance e varistor, è un componente elettronico realizzato con materiali semiconduttori come il silicio, non è altro che un interruttore.
Come interruttore, il transistor permette o impedisce il transito della corrente all’interno del circuito elettrico: il sistema può dunque assumere il valore binario di “0” o “1”, permettendo di realizzare i circuiti elettronici digitali alla base della logica booleana (le variabili possono assumere valori vero e falso, o in questo caso 0 e 1).
Il circuito elettrico è composto dalla porta (gate), dalla sorgente (source) e dal pozzo (drain).

Per chi non avesse le basi di informatica/elettronica o su come funziona la logica booleana applicata ai circuiti:
A 0, corrisponde un circuito aperto, non consente il passaggio di elettricità.
Ad 1, il circuito è chiuso ed è quindi collegato, permettendo il passaggio di corrente.
Ogni microchip (processore o memoria) è composto da miliardi di transistors che permettono di archiviare dati o eseguire le istruzioni e gli algoritmi dei vari software informatici.
I transistor possono essere usati anche come amplificatori e sono infatti alla base dell’elettronica analogica, ma riguarda anche altri ambiti.
Quest’ultimo è l’elemento cardine dell’elettronica digitale, averne di più, aumenta la capacità di calcolo aritmetica e logica correlato al processo produttivo.
Shader Processing Unit
Le Unità Shader o SPU (Shader Processing Unit) sono dei blocchi fondamentali in una scheda grafica che si occupano delle operazioni di shading (tradotto ombreggiatura).
Le SPU si occupano degli effetti di rendering vero e proprio di una scena, e sono spesso indicati come numero di CUDA cores (Nvidia) o di Stream Processors (AMD).
Le unità shader sono costruite in maniera diversa da Nvidia e AMD, quindi i CUDA cores (Prima Processing Core) e gli Stream Processor (Prima ATI Stream) non sono direttamente paragonabili (la potenza di un CUDA non è in rapporto 1:1 con quella di uno Stream Processor).
La posizione, il colore, gli effetti nonché le texture, i vertici e il numero di pixel di un oggetto sono informazioni messe insieme secondo un algoritmo implementato dalle SPU per costruire la scena virtuale, algoritmo che può cambiare mentre la scena stessa è mostrata all’utente.
Ogni “effetto” da applicare va a finire in una pipeline (coda) prima di essere processato.

Un tempo le unità shader erano divise fra Pixel Shaders (che si occupavano del colore, per mostrare a video vari effetti come le esplosioni) e Vertex Shaders (che avevano la responsabilità del trasformare o deformare pixel e quindi di comporre anche il movimento).
Il risultato finale era una combinazione delle soluzioni elaborate dai due tipi di unità.
Questo poteva comportare latenze di calcolo non indifferenti, in quanto i primi potevano dover aspettare il prodotto dei secondi o viceversa.

Questa distinzione è scomparsa, perché sono state affidate ad un’architettura a shader unificati, Unified Shader Model o Shader Model 4.0.
Nel quale vengono gestite le 3 tipologie di shader: Pixel Shaders, Vertex Sharders, e Geometry Shader.
Quest’ultima caratteristica è stata introdotta con DirectX 10.
Forma reale di un chip grafico

Il chip in questione è un GF100 (GTX 485).

A destra è il diagramma di un’altra GPU che sfrutta la medesima base con chip GF100, ma con alcune zone disabilitate (GTX 465) per differenziare l’offerta e per recuperare alcuni chip con aree danneggiate.

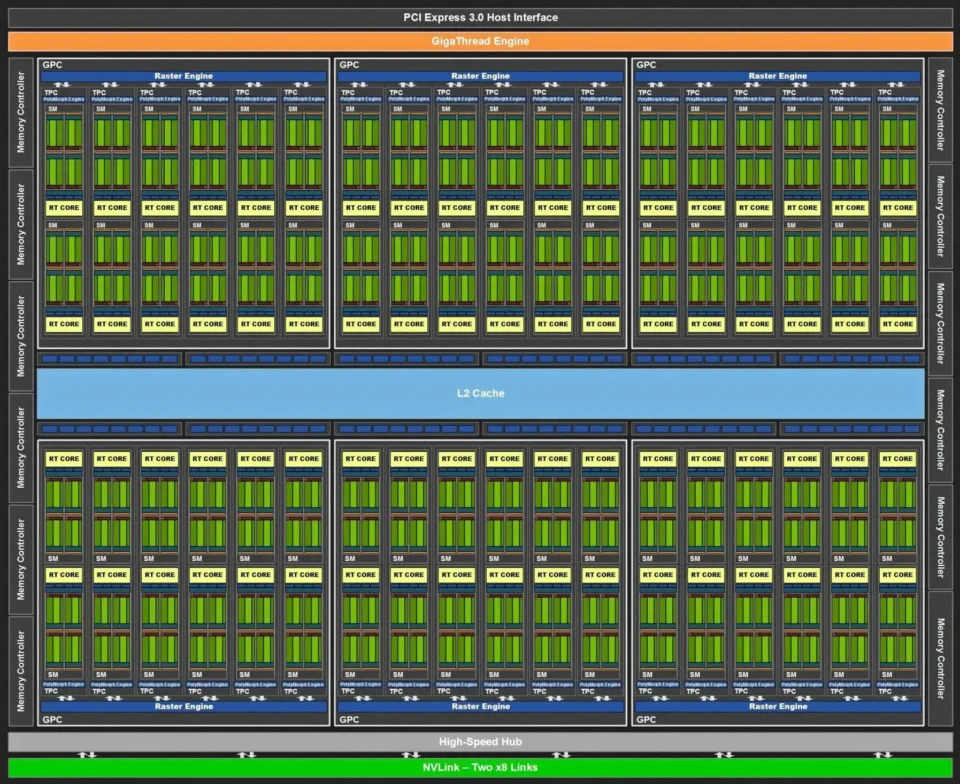
Su questo diagramma è riportato uno dei 4 GPC (acronimo di Graphic Processing Cluster).
Con la parola Cluster si intende generalmente un gruppo ben definito e raggruppato di core in una zona delimitata.

Zoom all’interno del Polymorph Engine.
Il Polymorph Engine (in basso nel GPC) racchiude tutti gli stadi di tipo fixed function che compongono la prima parte della pipeline grafica dedicata alle operazioni geometriche mentre il Raster Engine (in alto nel GPC) gli elementi di tipo fixed function che concorrono alle operazioni di rasterizzazione.

Zoom ancora più approfondito di un singolo Streaming Multiprocessor.
Al suo interno vediamo ben 32 Cuda Core sul quale è riproposto un ulteriore zoom nell’immagine stessa.
Memoria Video

La Memoria Video ha una sua frequenza e una dimensione variabile in base alla scheda.
Quest’ultima è la memoria video sulla quale la GPU può elaborare e dove viene memorizzato il framebuffer.
È una memoria buffer della scheda video nella quale vengono memorizzate le informazioni destinate all’output per la rappresentazione di un intero fotogramma.
La frequenza di clock della memoria è la frequenza massima espressa in Megahertz (MHz) alla quale può operare la memoria stessa.
La frequenza di clock della memoria scala a seconda dell’operazione che la scheda grafica sta compiendo, più alta è più la memoria è veloce, e quindi più aumenta il memory bandwidth.
Sebbene sia ancora chiamata VRAM, quest’ultima è in disuso da molti anni, già superata dalla WRAM delle Matrox, poi Multibank DRAM (MDRAM) e SGRAM (Synchoronus Graphics RAM), tutte memorie single-port.
In seguito si è passati alle dual-port, e quindi alle GDDR SDRAM (Graphics Double Data Rate).
Le loro caratteristiche principali sono frequenze di clock più elevate sia per il core DRAM che per l’interfaccia I/O, che fornisce maggiore larghezza di banda di memoria per le GPU.
Le GDDR SDRAM sono state succedute da GDDR2, GDDR3, GDDR4, GDDR5, GDDR5X, e GDDR6.
Queste tendono a risparmiare sempre più energia aumentando però il bandwidth.
La produzione di queste memorie è in genere affidata ad aziende esterne famose produttrici di memorie ovvero: Samsung, SK Hynix eMicron.
Curiosità dal mondo delle schede video
Famoso il caso delle RTX 2080/2080Ti con Memorie Video Micron in quanto quest’ultime a seguito dei test hanno subito una rapida degradazione delle memorie, che causano i famosi artefatti e lo stuttering.
Le memorie sono prodotte per reggere fino ai 95° oltre i quali iniziano a dare i problemi sopra citati.
Ciò si è ipotizzato per via del posizionamento di alcuni chip GDDR6 (nello specifico M6 ed M7), integrati praticamente sopra le tracce di alimentazione del PCB, queste passano tra le fasi PWM e il socket della GPU; che quindi ne aumentano la temperatura interna dei chip di memoria.
note sulle memorie delle GPU
Come controllo che memorie possiedo?
GPU-Z nella scheda Graphics Card alla voce Memory Type.
Cosa fare nel caso abbia memorie Micron?
Memorie di produzione antecedenti a Dicembre 2018 riscontrano quasi da subito (dall’acquisto o entro 2 mesi) questi artefatti, in tal caso vi conviene contattare il venditore/produttore per l’RMA.
Quali schede soffrono di questo problema?
Quelle che hanno Memorie GDDR6 Micron, ogni modello è potenzialmente sensibile a questo problema (dalle 2080ti alle 2060).
Ma perché la fascia bassa (RTX 2060) ne ha risentito di meno?
Perché sono uscite quando la notizia si è sparsa e quindi sono state subito troncate le spedizioni con le Micron.
Sono state inoltre creati nuovi tipi di memorie video, chiamate HBM (High Bandwidth Memory) con la collaborazione di Samsung, SK Hynix e AMD.
Quest’ultime, sono state implementate per la prima volta sulle R9 Fury, Fury X e Nano.
Le HBM sono state succedute da HBM 2, HBM 3, e HBM 4.
Esempio di impiego di una GPU in ambito videoludico
L’uso della Memoria Video è stato implementato sulla scheda per velocizzare le operazioni e i calcoli della GPU, la quale impiegherebbe troppo tempo ad accedere alla memoria principale della CPU con la quale litigherebbe per l’uso.
Un quantitativo insufficiente di Memoria Video può creare del bottleneck (tradotto in collo di bottiglia, in cui una grande mole di dati generati da un componente passa per una strettoia che riduce le sue prestazioni per arrivare ad un altro componente, quindi come una bottiglia).
In genere schede video da gaming e da editing di fascia alta possiedono molta più Memoria Video dovendo gestire una maggior quantità di dati a risoluzioni maggiori come il 4K o con carichi molto elevati come il rendering di video 4K o per lavori con GPGPU.

La Memoria Video serve inoltre a mantenere durante il Gaming informazioni come Texture, Frame Buffer, Depth Buffer, e altri asset richiesti per renderizzare un frame come Shadow Maps, Bump Maps, e Lighting Information.
Risoluzione, profondità del colore, quantità di texture, i vari filtri (anti-aliasing in primis avendo un effetto massivo sulla memoria video) e molto altro possono aumentare il peso sulla Memoria Video.
Per esempio poiché le immagini sono in genere a 32 bits per Pixel, significa in Full HD moltiplicare 32bits x 1920 x 1080 = 8,3 MB per un singolo Frame, mentre se saliamo di risoluzione in Ultra HD o 4K 32bits x 38240 x 2160 = 33,2 MB per singolo Frame.
Domande frequenti
Di quanta Memoria Video ho bisogno?
In Full HD sono consigliati un minimo di 4-6GB di Memoria Video, in Quad HD (2K) 6-8GB di Memoria Video, in Ultra HD (4K) minimo 8GB di Memoria Video.
Le cose si complicano ulteriormente se parliamo invece di Realtà Virtuale o VR.
Ma cosa succede quando saturiamo la Memoria Video?
Si tende ad avere stuttering oltre che un brusco calo degli fps, questo perché la memoria in eccesso deve essere comunque usata, ma viene messa nella memoria centrale (RAM), che è più lenta e impiega quindi più tempo.
Se quest’ultima si satura si deve passare alla memoria dello storage.
Video BIOS e Memoria ROM

Sono saldate su questo piano le Memorie ROM.
La Memoria ROM (Read Only Memory) è una memoria non volatile, il cui contenuto in genere non è modificabile ma può essere aggiornato.
In essa risiede il BIOS (Basic Input-Output System) della GPU, per essere più precisi viene chiamato Video BIOS, posizionato in genere sull’altro lato della scheda quello coperto dal Backplate per schede di recente fattura o già visibile sulle più vecchie.
Gran parte delle differenze tra schede video da gaming e schede video professionali risiede proprio qui.
Qui ritroviamo il Firmware della GPU, il quale permetterà alla scheda di avviarsi correttamente ogni qual volta accendiate il PC.
Questa fase prende il nome di “boot” o bootstrap” e permetterà la lettura delle informazioni necessarie per inviare in output i primi segnali video con la visione dello splash screen (schermata di caricamento).
Alcune Custom avanzate hanno anche due o più BIOS differenti in base al raffreddamento della GPU, se normale ad aria o se si utilizza l’impianto a liquido.
I BIOS delle schede video sono aggiornabili come quelli delle schede madri.
In questo caso l’aggiornamento ne migliora l’efficienza e in parte le prestazioni, potendo migliorare quindi voltaggi applicati e frequenze operative sia di base che in boost.
TDP e Connettori di Alimentazione

I connettori di alimentazione possono essere a 6, 8, 6+6, 6+8 o 8+8 Pin.
Le schede video più vecchie o di fascia più bassa spesso omettono questo connettore in quanto l’alimentazione della scheda madre (tramite il +12V) è sufficiente ad alimentarle.
In genere queste non devono superare i 5,5 Ampere di alimentazione definiti dal PCI-SIG (Peripheral Component Interconnect Special Interest Group, ovvero il consorzio che gestisce l’industria degli slot PCI-E).
Tutt’oggi le schede video, soprattutto di fascia molto alta, traggono beneficio dalla scheda madre per ottenere più potenza.
Il tutto viene misurato in watt che è l’unità di misura della potenza, non va confuso con il Wattora (Wh) e con i relativi multipli che sono una misura di energia (potenza × tempo) che corrisponde all’energia prodotta da 1 watt in un ora ovvero 3.600 Joule.
Per esempio su una scheda video da 180 W a consumo fisso accesa per 1 ora, abbiamo 180 Wh che corrispondono a 648.000 Joule di energia.
Immaginate questo consumo ogni giorno, va quindi moltiplicato per 24 ore, per 30 giorni in un mese avrete circa 129.600 Wh, parliamo quindi cifre abbastanza grandi e per questo in genere indicate come kilowattora (kWh) ovvero 129,6 kWh.
1 Watt equivale ad 1 Joule al secondo (1 J/s) ma equivale anche ad 1 Volt moltiplicato per gli Ampere (1 V × A).
1 Joule è quindi uguale alla formula inversa ad 1 W per secondo (W × s) ma equivale anche ad 1 Newton per metro (1 N m).
Spiegazione del TDP
Il TDP (Thermal Design Power) è un’indicazione del calore dissipato dalla scheda che andrà poi dissipato tramite il dissipatore (heatsink) e le ventole montate sulla scheda.
Spesso vediamo varie modalità impostabili per la scheda video tramite applicazione, ad esempio modalità silenziosa, modalità gaming/OC o modalità normale.
Possiamo infatti avere un cTDP (TDP Configurabile):
- TDP nominale: frequenza nominale e TDP della GPU.
- cTDP down: quando si desidera una modalità di funzionamento più fredda o più silenziosa, questa modalità specifica un TDP inferiore e una frequenza garantita inferiore rispetto alla modalità nominale.
- cTDP up: quando è disponibile un raffreddamento extra, questa modalità specifica un TDP più alto e una frequenza garantita più elevata rispetto alla modalità nominale.
Il TDP non è quindi la massima potenza che una GPU potrebbe mai generare (quello è il picco di potenza) ma più realmente è la potenza massima che utilizzerebbe durante un applicativo per il quale è stata creata.
Spesso viene definito SDP ovvero Scenario Design Power, il TDP diviso per determinati scenari.

Come possiamo vedere la Vega 64 ha da specifiche un TDP di 295W eppure guardando questo grafico, li sfora arrivando a picchi di oltre 330W (la reference ad esempio aveva picchi di anche 380 Watt).
Questi picchi sono chiamati picchi di potenza, e sono quelli su cui noi dobbiamo anche basare la scelta dell’alimentatore.
Vien da sé che una CPU da 100W (i cui picchi possono arrivare a 150W in OC) ed una Vega da 295W (i cui picchi in OC possono sfiorare i 400W) a cui si sommano approssimativamente un 50 W (tra LED, dissipatore, hard disk, MB etc.) rappresentano il consumo massimo di 600W in tutti i picchi e che quindi un alimentatore da 650W o più rappresenta la miglior scelta per queste componenti.
Power Rating
Il Power Rating è la massima potenza entrante in quel determinato componente elettrico in base alle specifiche dichiarate dal produttore, sebbene anche questa si differenzi in due modi ovvero l’Average Power Rating, in genere dichiarato, e il Maximum Power Rating.

Il sistema di raffreddamento di una scheda video può essere progettato per un TDP di 180W.
Ciò significa che può dissipare 180 Joule di calore al secondo, senza eccedere la temperatura di giunzione dei transistor (abbreviato in Tj) in inglese chiamata transistor junction temperature, è la più alta temperatura alla quale un semiconduttore può lavorare.
La temperatura è uguale all’ammontare di calore trasferito dalla junction al case, moltiplicato per la resistenza termica che ritroviamo tra la junction e il case (abbreviata Rjc).
Il calore trasferito ci darà la temperatura del package a contatto con l’heatsink (dissipatore), questo valore è la temperature del case (abbreviato in Tc) in inglese case temperature.
L’heatsink fa da collegamento (e da traferimento) tra la Tc e la Ta, ovvero tra la Case Temperature e la Ambient Temperature.
Il TjMax è massima temperatura della giunzione per il funzionamento del chip, oltre la quale abbiamo la possibilità di avere un malfunzionamento temporaneo o permanente.
La temperatura interna (Tj)
La temperatura interna (Tj) viene misurata da un sensore.
Se il core raggiunge il suo TjMax, questo attiverà un meccanismo di protezione per raffreddare il processore chiamato Thermal Throttling (traducibile come strozzamento termico), ovvero un abbassamento delle frequenze operative o il loro arresto.

La Tj non è facilmente misurabile con una termocoppia o una telecamera infrarossi.
Viene in genere misurata indirettamente tramite il voltaggio/temperatura, e resa più accurata da tecniche JEDEC come JESD 51-1 e JESD 51-51.
In genere il calcolo è fatto dalla temperatura ambiente a cui si sommano la resistenza j-a (dalla junction all’ambiente) moltiplicata per la potenza dissipata:
Tj = Ta + (R θja × PD)
VRM, Fasi e PWM

I VRM (Voltage Regulator Module) sono dei moduli regolatori delle tensioni in entrata dall’alimentatore dirette verso la GPU e la VRAM.
Sono costituiti dal Voltage Controller (Regolatore di Tensioni/Voltaggi), dal PWM, e dalle Phases (Fase).
Il PWM (Pulse Width Modulation) è il modulatore di larghezza degli impulsi.
Le Fasi (Phases) sono a loro volta composte da Condensatori a stato solido (Capacitor), Induttori (Choke) e più MOSFETS.
Un solo condensatore + un solo Choke + i relativi MOSFETS formano un’unica Fase.
Per ogni gruppo quindi abbiamo una fase.
Tutto ciò garantisce alla GPU e alla VRAM una potenza stabile e “pulita”.
Una scheda video che possiede più VRM è in grado di suddividere più facilmente il carico tra più VRM e quindi di conseguenza diminuire il lavoro per ogni singolo VRM e le temperature.
C’è una porzione di VRM dedita alla sola Memoria Video.
In genere è un solo gruppo di VRM, ma in alcune custom potrebbe essere anche 2 o 3.
Ad esempio sulla MSI RTX 2080Ti Lightning Z ne ritroviamo ben 3 per la sola Memoria Video.
Solitamente scrivono Fasi 12+2 o 5+1 o 6+3, poiché il primo numero sono le fasi dedicate alla sola GPU, mentre il secondo numero sono le fasi dedicate alla sola Memoria Video.
In genere il numero di VRM è modificato da ogni produttore di schede video, creando un PCB Custom (Circuito Stampato modificato) sul quale agire.
Le Top Custom avranno sempre un PCB di maggiori dimensioni per riuscire a contenere più VRM, e in genere, un migliore modulo di raffreddamento.
Backplate

Il Backplate nasconde tutta la parte anti-estetica nel retro del PCB (il lato opposto alle ventole) ed è utile anche ai fini della dissipazione del calore.

Attualmente vi sono schede video sempre più grandi, spesse e pesanti ma l’80% della vostra scheda video è composto dall’ Heatsink (dissipatore) e dalle Ventole, oltre che dai LED RGB in alcuni casi.

Il calore sprigionato della GPU, dalla VRAM e dai VRM, per irraggiamento e convezione, viene trasmesso all’ Heat Sink fatto in alluminio e/o rame (materiali con alta conducibilità termica) tramite pad termoconduttivi o paste termoconduttive.
L’Heat Sink (Dissipatore), in genere, è formato da dei tubi in rame chiamati Heat Pipe, e da una parte a forma di lamelle (definito come gruppo lamellare) questo per aumentare l’efficienza nella sottrazione di calore (aumento del rapporto superficie/volume) al cui apice ritroviamo delle ventole, le quali creano un flusso d’aria che asporta il calore trasferendolo lontano dal componente.

tipologie di gpu
Vi sono delle differenze tra due tipi di raffreddamento ad aria, biventola o triventola che normalmente vediamo e le Blower.
Le Blower acquisiscono aria dalla parte bassa del pc, dove l’aria è più fredda, e la immettono nei gruppi lamellari dirottandole fuori dal case, abbassando la temperatura interna rispetto alle versioni normali.
Una Blower può essere preferita per mancanza di spazio e non si necessita di overclock della GPU, mentre magari potrebbe essere elevata la temperatura interna per la presenza di molti Hard Disk.
Le Custom biventola e triventola hanno una miglior dissipazione della GPU, dei VRM e della Memoria Video.
L’aria non viene continuamente spinta fuori dal case passando per tutta la scheda video quindi l’aria calda dei VRM passa sopra l’aria calda delle memorie e poi della GPU per poi uscire, ma viene estratta verso la parte bassa del case che “dovrebbe” essere portata fuori dalla ventola frontale più bassa che aspira aria fredda e dovrebbe mandare l’aria calda in uscita dalla scheda video attraverso le feritoie posteriori.
Le schede video chiamate Barebone che sono completamente prive di sistema di raffreddamento, ma hanno un PCB modificato, per applicare più facilmente un sistema custom senza dove smontare il dissipatore.
Esistono le schede video con dissipazione passiva ovvero senza alcuna ventola, ma solo con il gruppo lamellare, in genere sono solo per schede con un basso TDP.
Negli ultimi anni i sistemi di raffreddamento si sono evoluti sulle schede video, da lì sono nati i sistemi di dissipazione a liquido All in One.
Vi sono schede video già predisposte per l’impianto a liquido custom o che vengono moddate (modificate) tramite un GPU Waterblock.
Tramite alcuni adattatori (come l’NZXT Kraken G10 o il Corsair Hydro Series HG10) è possibile attaccare un dissipatore a liquido per CPU alla scheda video.
Supporti e accessori per le schede video

L’enorme peso da parte degli Heatsink delle schede video ha costretto molti a montare anche un Bracket, ovvero un supporto che sostenga la scheda video dal basso oltre a dover rinforzare la connessione con la scheda madre con dei PCI-E in metallo.
In genere sono supporti in metallo montati a parte, ma potrebbero essere inclusi (molto raro) nel case (Lo Sharkoon Pure Steel è un esempio) oppure possono essere fatte in plexyglass o alluminio con personalizzazioni varie.

Per evitare che il peso pieghi lo slot PCI-E, un ulteriore soluzione è stata quella di togliere la scheda video dalla motherboard e posizionarla verticalmente.
In genere questa modifica viene fatta utilizzando un Vertical Mount il quale deve essere compatibile con il case e deve avere un PCI-E Riser.
La soluzione ha principalmente un fine estetico più che pratico, in quanto viene mostrata la parte delle ventole invece che la parte laterale, generalmente più accattivante.
Questa opzione però ha alcune problematiche:
- Il Riser, se non di qualità, potrebbe ridurre le prestazioni.
- L’aria calda viene continuamente spinta con il plexyglass/vetro temprato/alluminio, soffocando in parte l’airflow della scheda.
- Posizionando la scheda video in verticale si toglie la possibilità di utilizzare gli slot inferiori se non tramite un ulteriore riser e un posizionamento non regolare dell’altra scheda che può essere una seconda scheda per il Multi-GPU o un ulteriore tipo di scheda come schede audio, schede Wi-Fi etc.
Interfaccia di connessione Scheda Video ↔ Scheda Madre

Parliamo dell’interfaccia di connessione più diffusa degli ultimi anni, ovvero la PCI-Express 3.0 x16 (sostituito dall’attuale PCI-Express 4.0).
Questo slot fisico posto sulla scheda madre consente l’inserimento della scheda video, con la quale può scambiare i dati e alla quale porta alimentazione.
Da parte loro, le schede video attuali, devono essere compatibili con lo slot PCI-Express (Le generazioni sono retro-compatibili 1.0, 2.0, 3.0, 4.0 etc.) attualmente diventato lo standard condiviso da tutte le schede madri e le schede video.
Storia delle Interfacce di Connessione GPU
Il primo BUS di connessione parallelo fu l’ISA (acronimo per Industry Standard Architecture, nel 1981) migliorato con l’EISA (acronimo di Extended-ISA, nel 1988), e poi con il VESA (acronimo di Video Electronics Standards Association nel 1995), vennero tutti rimpiazzati dal PCI (acronimo per Peripheral Component Interconnect, 1993) e dalle sue tante generazioni.
Nel frattempo nel 1996-1997, in seguito all’accelerazione 3D, nasce e si diffonde lo standard AGP (acronimo per Accelerated Graphics Port), basato sulla PCI 2.1.
L’AGP è la prima interfaccia (posta sulle schede madri) nata esclusivamente per le schede grafiche che si è migliorata nel tempo da AGP x1 (AGP 1.0) in AGP x2 e AGP x4 (AGP 2.0) ed infine in AGP x8 (AGP 3.0) per poi essere sostituita dalle PCI-Express.
Dato che le AGP rappresentavano l’unica fonte di alimentazione della scheda video, ci fu la necessità di cambiare l’alimentazione da 1,5 V a 3,3 V ed eventualmente essere retro-compatibili.
Per questo abbiamo 3 tipi di AGP: AGP 1,5 V; AGP 3,3 V e AGP Universal.
Dall’AGP 3.0, si è capito che l’alimentazione non bastava poiché 50W erano insufficienti e hanno iniziato ad aggiungere anche un connettore Molex sulla scheda video.

IL PCI
Nell’anno 2002 nacque lo standard PCI-E 1.0 (in slot x1, x4, x8, x16), che era un BUS seriale (il primo non più parallelo) che permetteva di rimuovere il connettore Molex per le schede di fascia media e bassa, e di erogare fino a 75W, oltre a dare più banda passente.
Successivamente nel 2006 ci fu l’aggiornamento al PCI-E 2.0 (in slot x1, x4, x8, x16), retrocompatibili con i PCI-E 1.0, ma lo migliorano in ampiezza di banda raddoppiandola da 2,5 GT/s (Gigatransfer al secondo) a 5 GT/s; inoltre aumenta la frequenza da 100MHz a 250MHz.
A seguito nel 2010 nasce lo standard attuale ovvero il PCI-E 3.0 che porta la banda a 8 GT/s.
Durante il 2018 è stato presentato il PCI-E 4.0 con 16 GT/s, le prime schede madri a possederlo sono le AM4 X570 di AMD uscite nel 2019.
Il 2 Giugno 2019 è stato presentato il PCI-E 5.0 con 32 GT/s (128GByte/s di Bandwidth) con retrocompatibilità per i vecchi PCI-E.

PCI-E Riser

Già dai PCI-E 2.0 si iniziano inoltre a sviluppare delle prolunghe definite PCI-E Riser.
Tutto ciò per poter spostare la propria scheda video dalla posizione orizzontale sulla scheda madre ad una qualsiasi altra collocazione, attualmente è molto usato per i fini estetici il Vertical Mount GPU con appunto il PCI-E Riser.
Nasciata del VGA

DP, HDMI, DVI, VGA
VGA (acronimo per Video Graphics Array) introdotto da IBM nel 1987, è un connettore a 15 pin con un segnale di tipo analogico, e quindi non trasporta l’audio.
È stata la base di tutto ed una delle interfacce più importanti presenti sulla scheda video anche se ormai è obsoleta (risoluzione massima 640×480), è il “denominatore comune” che tutte le schede grafiche devono essere in grado di gestire, ancor prima di caricare driver.
Lo splash screen (la schermata di caricamento) che appare all’avvio di windows, è visualizzato mentre la macchina sta lavorando in modalità VGA (non ha ancora caricato i driver specifici) ed è anche il motivo per il quale la schermata ha sempre bassa risoluzione e profondità di colore.
La risoluzione fu superata prima dal SVGA o Super VGA, che identifica ormai una risoluzione di 800×600 e poi dall’XGA, che identifica una risoluzione di 1024×728, e con altre svariate risoluzioni e standard (WVGA, SVGA, SWVGA, XGA+, SXGA, SXGA+, WXGA, UXGA, QXGA, WSXGA, WSXGA+, WUXGA, WQXGA, QSXGA).
OUTPUT VIDEO successivi
DVI (acronimo per Digital Visual Interface) introdotto nel 1999, con segnale analogico e/o digitale con un’evoluzione da DVI-A (solo analogico) a DVI-I (ibrido sia digitale sia analogico) e a DVI-D (solo digitale) con una risoluzione fino al 2560×1600 (WQXGA) a 60Hz o in Full HD (1920×1080) fino a 144Hz.
Ci sono cavi DVI Single Link che si limitano quindi al Full HD e cavi DVI Dual Link che riescono invece superano il Full HD arrivando al WQXGA.
HDMI (acronimo per High Definition Multimedia Interface) introdotto nel 2002, con segnale digitale con audio annesso.
Nel corso degli anni è stato aggiornato diverse volte con versioni più recenti, in grado di supportare risoluzioni e frequenze più elevate.
L’HDMI 1.0 poteva utilizzare il FHD (1920×1080) e l’WUXGA (1920×1200) a 60Hz ma con l’HDMI 2.0 si è arrivati al 4K a 60 Hz.
DP (acronimo per Display Port) introdotto nel 2006, con un segnale digitale con audio annesso.
La più recente versione DP 1.4 regge una risoluzione 8K a 60Hz o 4K a 120Hz e supporta inoltre la tecnologia G-Sync e Free-Sync.

Piccola nota per il VR (Realtà Virtuale), viene predisposta in alcune schede video l’uscita USB Type-C insieme alle uscite video per i sensori VR.
Sempre per il VR alcuni case portano l’uscita HDMI sul frontale in modo da creare una prolunga dal back della scheda video al frontale del case.
Schede Video Esterne

Interfaccia di connessione tra schede video esterne e PC:
ExpressCard, USB Type-C, Thunderbold 3, eGPU, eGFX.
Multi-GPU: SLI, CrossFireX e NV LINK

L’utilizzo del calcolo parallelo è fondamentale nelle scene 3D, provate ad immaginare la quantità di elementi, di figure geometriche da ruotare o traslare o da ridimensionare secondo i requisiti per il prossimo fotogramma di animazione del gioco.
Questi oggetti possono essere composti sia da pochi che da migliaia di triangoli; inoltre ogni triangolo deve essere proiettato sullo schermo anche cose che non vediamo (dal retro agli oggetti frontali, ad oggetti che sono più lontani dallo spettatore e sono coperti da quelli più vicini).
Tutto questo considerando una risoluzione che genera milioni di pixel e va di pari passo aumentando nel tempo, aumentando il numero di pixel da renderizzare senza contare che non si sono menzionati i programmi di texture mapping o vertex e pixel shader.
Tutte queste operazioni devono essere fatte in 1/60 di secondo per poter avere una minima fluidità o per i giocatori più esigenti addirittura 1/144 di secondo.
Il mondo delle schede video si evolve molto più velocemente di quello dei processori, ma spesso non basta e quindi l’unico modo per superare ulteriormente questo limite è l’utilizzo di schede in parallelo, motivo per cui nasce lo SLI o il CrossFire.
NVlink di Nvidia

Parliamo ora dell’interfaccia di connessione tra schede video ovvero l’utilizzo di tecnologie multi-GPU: SLI, CrossFireX, e NV LINK.
N.B.: multi-GPU (o mGPU) è usato per indicare due schede in parallelo che utilizzano lo SLI o il CrossFire.
È errato utilizzare la parola SLI per indicare il CrossFire.
Il multi-GPU consente a due, tre o quattro unità di elaborazione grafica (GPU) di condividere il carico di lavoro durante il rendering di grafica 3D in tempo reale.
Idealmente si utilizzano due (o più) schede identiche in cui una è la Master (in genere è posta al primo slot PCI-E) e le altre sono le Slaves.
Ognuna fa il proprio lavoro, ma tutte le informazioni sono mandate all’unità Master tramite il connettore Bridge che provvederà all’output finale dell’immagine inviandola al monitor.
Funzionamento di nvlink
NVLink rompe questo limite del Master-Slave, creando una collaborazione tra le due GPU a livello paritario che ne aumenta di molto le performance.
NVLink porta la velocità di trasmissione per corsia da 8 GT/s (PCie 3.0) a 20 GT/s (NVLink 1.0) per poi arrivare con NVLink 2.0 a 25 GT/s per corsia che tradotto in 8+8 corsie sono quindi 200 Gbit/s (che è uguale a 25 GByte/s) quindi 25 GByte/s + 25 GByte/s su di un unico grande collegamento.
Per esempio nel caso della RTX 2080 oppure su due grandi collegamenti come le RTX 2080Ti che quindi raddoppiamo a 50 GByte/s + 50 GByte/s quindi un totale di 100 GByte/s* per le RTX 2080Ti e 50 GByte/s* per le RTX 2080.
Naturalmente confrontato con il mondo professionale parliamo di ben altre cifre, NVLink di 2 NVidia Tesla V100 porta a valori quali 25 GByte/s + 25 GByte/s ma moltiplicati per ben 6 grandi collegamenti quindi un totale di 150 Gbyte/s + 150 Gbyte/s, per un totale di ben 300 GByte/s* per le Tesla V100.
Multi-GPU
Per aumentare le prestazioni, nel 1998 si è pensato di unire la potenza di calcolo di più schede video insieme.
Tale tecnologia venne chiamata SLI (acronimo di Scan Line Interleave).
Il primo ad introdurlo fu 3dfx sulle sue Voodoo 2 con accelerazione 3D.
Con un piccolo cavo venivano collegate alternando linee di pixel per ogni scheda.
Questo però non bastò per mantenere a galla 3dfx, anche perché spesso causava più che altro disastri grafici.
Alla fine fu assorbita da NVIDIA nel 2001.
Nell’anno 2004 decise di riproporre questa tecnologia sempre con l’acronimo SLI ma con un altro significato ovvero Scalable Link Interface.
L’introduzione del nuovo SLI iniziò con le Motherboard che utilizzavano non più l’AGP, ma il PCI Express; inoltre le schede dovevano essere perfettamente identiche.
evoluzione dello sli e del crossfire
Nel 2005 ATI (acquistata da AMD nel 2006) diede la sua risposta nel mercato allo SLI con il CrossFire.
Questa fu la sua personale soluzione per il multi-GPU che creò una divisione tra le schede in Master e Slave.
Nel 2006 si arrivò al supporto del Quad-SLI (differente dal Quad Way SLI) con ben 4 schede video in parallelo.
Inizialmente le mainboard non possedendo 4 slot x16 si usarono solo due slot e delle “GPU doppie” con due PCB uniti (NVIDIA GeForce 7950 GX2).
In entrambi i casi le prestazioni miglioravano di poco soprattutto per le applicazioni DirectX 9.
Queste erano limitate dalle API (acronimo per Application Programming Interface), che sono delle librerie software.
Le API permettono di evitare ai programmatori di riscrivere ogni volta tutte le funzioni necessarie al programma dal nulla.
Ovvero dal basso livello, rientrando quindi nel più vasto concetto di riuso di codice.
Nel 2007 ATI si evolse con il supporto per 4 schede in CrossFire, il quale venne rinominato CrossFire X.
Da lì nacque la possibilità di utilizzare il CF anche per GPU doppie come l’HD 3870 X2.
Nel 2008 arrivò sul mercato il Three-way SLI ovvero il supporto allo SLI per 3 schede video in 3 connettori fisici.
Ogni scheda veniva collegata tramite un bridge esterno alle altre due.
Successivamente nel 2014 venne annunciato l’NV Link, che utilizzava un’interfaccia di comunicazione proprietaria ad alta velocità (NVHS) sviluppata da Nvidia.
A seguito, nel 2016 venne implementato anche nelle schede video Pascal; con Volta invece vi fu avuto un miglioramento con l’NV Link 2.0.
Funzionamento SLI 3dfx e NVIDIA

Nella tecnologia Scan Line Interleaving di 3dfx, il carico di lavoro era ripartito tra le due schede video demandando ad una scheda l’elaborazione delle linee pari dello schermo e all’altra l’elaborazione delle linee dispari.
Successivamente le due scene venivano fuse per ottenere l’immagine finale.
Questo approccio risultò essere molto efficiente per alcuni tipi di applicazioni e in certi ambiti le prestazioni subivano effettivamente quasi un raddoppio.


La tecnica di ripartizione del carico di lavoro alla base della tecnologia Scalable Link Interface invece è basata su un principio completamente differente dal suo omonimo.
Invece di far elaborare le linee pari dello schermo ad una GPU e quelle dispari all’altra, NVIDIA ha deciso di utilizzare due modalità di ripartizione del carico di lavoro:
Split Frame Rendering (SFR)
Con questa tecnica il rendering permette di suddividere la scena orizzontalmente in due parti da assegnare alle due schede.
La suddivisione non è necessariamente al 50%, ma varia dinamicamente da un fotogramma all’altro.
Il driver analizza infatti l’immagine e definisce le percentuali da assegnare a ciascuna scheda video (in modalità SFR).
Questo nuovo approccio consente di bilanciare in maniera ottimale il calcolo in quanto una suddivisione statica al 50% sarebbe risultata completamente inefficiente in casi, come nei simulatori di volo, dove, ad esempio, la zona inferiore dello schermo è solo un’immagine statica e quella superiore contiene invece moltissimi poligoni ed è interamente 3D.
Alternate Frame Rendering (AFR)
Il rendering della scena viene eseguito in modo sequenziale, con la prima scheda che renderizza i frames pari e l’altra quelli dispari.
In genere è quella più efficiente e con la miglior resa a livello di produzione di fps.
Quando si utilizza lo SLI con AFR, il framerate può essere spesso inferiore al framerate riportato dalle applicazioni di benchmarking e può anche essere più povero del framerate del suo equivalente a GPU singola.
Questo fenomeno è noto come micro stuttering.
SLI AA (Anti-Alising)
Questa ulteriore modalità non migliora le performance a livello di fps, ma aumenta la qualità dell’immagine.
Poiché una scheda singola al massimo del dettaglio può in genere sopportare un filtro Anti-Alising x4 o x8, con questa configurazione si può raddoppiare se non quadruplicare l’anti-alising arrivando a x16 o x32.
L’Anti-Alising è un filtro che viene usato per migliorare i contorni.
NVIDIA ha deciso di rendere disponibili entrambi i criteri in quanto non esiste la modalità migliore in assoluto.
A seconda dell’applicazione in esecuzione, può essere migliore una o l’altra modalità.
Per semplificare la scelta sono disponibili dei profili ottimizzati per un grande numero di applicazioni 3D e, semplicemente selezionando il profilo desiderato, è possibile sfruttare al meglio le potenzialità di una configurazione SLI.
La configurazione SLI infatti, non è sempre a two-way ma può essere in three-way o quad-way SLI e in base a questa scelta si possono scegliere migliori opzioni di ripartizione:


I dati sui vertici, elaborati dal processore, vengono inviati alla prima scheda video e da questa ultima vengono duplicati alla seconda, utilizzando il connettore posto nella parte superiore delle due schede.
Questo permette a ciascuna scheda video di avere a disposizione le informazioni necessarie per la generazione della scena 3D.
Una volta che il frame è stato generato dalla scheda video secondaria, i dati vengono inviati al frame buffer della scheda principale, quella alla quale viene collegato il monitor, e da quest’ultima mandati sullo schermo.
Accorgimenti in merito allo SLI
Lo SLI permette l’utilizzo solo di schede uguali con lo stessa identica GPU, possono quindi essere di diversi partner (esempio: MSI GTX 1070 + ASUS GTX 1070).
Il CrossFire X permette l’utilizzo di schede diverse (con qualche limitazione), ma la più potente si adeguerà alla più lenta (esempio: RX 570 + RX 580, la RX 580 funzionerà come una seconda RX 570).
NVIDIA, inoltre, attua una politica aziendale di scegliere quali GPU possano essere messe in SLI e quali no, nel caso della generazione Pascal, GPU al di sotto della GTX 1070 (esclusa) non potevano essere messe in SLI quindi la GTX 1060 non poteva essere utilizzata per il multi-GPU.
Funzionamento CrossFire
Dopo aver parlato delle modalità di ripartizione di NVIDIA passiamo ora a quelle di AMD abbastanza simili:
SuperTiling: Modalità standard
Divide lo schermo in una scacchiera e i riquadri vengono renderizzati da ciascuna delle due schede (paragonando lo schermo a una scacchiera, una scheda renderizza i riquadri neri, l’altra quelli bianchi).
Il SuperTiling supporta tutte le applicazioni Direct3D, ma non le OpenGL.
È la modalità che offre il guadagno prestazionale minore.
La computazione della geometria della scena non può essere divisa tra le due schede.
Inoltre questa modalità funziona solo con schede aventi lo stesso numero di pipeline.
Scissor
Anche conosciuto con il nome di Split Frame Rendering (SFR), utilizzato nello SLI di NVIDIA, divide lo schermo in due rettangoli orizzontali.
È la modalità predefinita per le applicazioni OpenGL.
Le prestazioni però sono analoghe a quelle del SuperTiling, anche se in teoria il primo dovrebbe essere migliore in quanto vi è una maggiore probabilità che i calcoli siano equamente distribuiti tra le due schede.
Con la modalità Scissor il sistema deve calcolare il punto di divisione per bilanciare il carico tra le GPU.
Alternate Frame Rendering (AFR)
Una scheda renderizza i frame pari, l’altra quelli dispari.
Questa modalità esibisce le prestazioni migliori.
Il problema è l’incompatibilità con i giochi che utilizzano funzioni render-to-texture, in quanto una scheda non ha accesso alla memoria texture dell’altra.
Come NVIDIA, AMD utilizza nei driver dei profili per abilitare l’AFR nei giochi compatibili, ma non permette l’impostazione manuale per i giochi OpenGL.
Quando si utilizza CrossFire con AFR, il framerate può essere spesso inferiore al framerate riportato dalle applicazioni di benchmarking e può anche essere più povero del framerate del suo equivalente a GPU singola.
Questo fenomeno è noto come micro stuttering.
CrossFire Super AA
Questa modalità non è studiata per incrementare il framerate.
Ma per migliorare la qualità delle scene utilizzando il Super AA (Super Antialiasing), che è in grado di raddoppiare il fattore di antialiasing (es. 4x, 8x, 12x) senza alcun calo nel framerate.
N.B.: Il CrossFire X permette l’utilizzo di schede diverse (con qualche limitazione).
La più potente si adeguerà alla più lenta (esempio: RX 570 + RX 580, la RX 580 funzionerà come una seconda RX 570).
Lo SLI permette l’utilizzo solo di schede uguali, possono però essere di diversi partner (esempio: MSI GTX 1070 + ASUS GTX 1070).
Bridge

Nvidia ha 3 tipi (4 se si conta il recente NVLink) di bridge SLI:
- Bridge standard (400 MHz Pixel Clock e 1GB/s di larghezza di banda)
- LED Bridge (540 MHz Pixel Clock)
- Bridge a larghezza di banda elevata (HB Bridge, ovvero High-Bandwidth) (650 MHz Pixel Clock e 2GB/s Bandwidth)

l Bridge standard è tradizionalmente incluso con schede madri che supportano SLI ed è consigliato per monitor fino a 1920 × 1080 e 2560 × 1440 @ 60 Hz.
Il LED Bridge è venduto da Nvidia, EVGA, e altri ed è consigliato per monitor fino a 2560×1440 @120 Hz+ e 4K.
I LED Bridge possono funzionare solo con l’aumento del Pixel Clock se la GPU supporta quel determinato clock.
Nel caso High-Bandwidth Bridge è venduto solo da Nvidia ed è consigliato per monitor fino a 5K e Surround.
In ambito elettrico c’è poca differenza tra il normale ponte SLI e il ponte SLI HB.
È simile a due ponti regolari combinati in un PCB.
La qualità del segnale del ponte è migliorata, ciò avviene grazie il ponte SLI HB.
Quest’ultimo ha una lunghezza della traccia regolata per assicurarsi che tutte le tracce sul ponte abbiano esattamente la stessa lunghezza.
Tipologia di Bridge
Esistono Bridge per connettere schede video posizionate nello slot 1 e 2 (two-way SLI), oppure sullo slot 1 e 3 o sugli slot 1 e 4.
Così come esistono bridge che connettono 1, 2 e 3 slot (three-way SLI), e bridge che connettono 1, 2, 3 e 4 slot (quad-way SLI).

Il bridge SLI viene utilizzato per ridurre i vincoli di larghezza di banda e inviare i dati tra entrambe le schede grafiche direttamente.
È possibile eseguire SLI senza utilizzare il connettore bridge su una coppia di schede grafiche di fascia bassa con i driver adatti.
Poiché queste schede grafiche non utilizzano la stessa larghezza di banda, i dati possono essere trasmessi solo attraverso i chipset sulla scheda madre.
Tuttavia, se sono installate due schede grafiche di fascia alta e il bridge SLI viene omesso, le prestazioni ne risentiranno gravemente, poiché il chipset non ha abbastanza larghezza di banda.
AMD nella fascia entry level e mainstream, non utilizza un Bridge ma utilizza solo il bus PCI-E.
Lo utilizza invece nella fascia alta infatti, il nuovo Bridge CrossFire ha un’ampiezza di banda maggiore di quello utilizzato nello SLI, inoltre permette l’inserimento di schede video aggiuntive, in previsione di un eventuale utilizzo per i calcoli fisici.
Gli attuali SLI Bridge HB non sono compatibili con la serie di schede grafiche RTX 20XX del 2018.
Queste schede utilizzano NVLink e richiedono un bridge NVLink a 3 slot o 4 slot.
Solo due schede possono essere collegate con NVLink; lo SLI three-way e quad-way non sono possibili utilizzando il bridge NVLink.
Hybrid SLI nei Notebook
Nvidia Optimus è una tecnologia di commutazione della GPU creata da NVIDIA.
In base al carico di risorse generato dalle applicazioni software client, passa senza interruzioni tra due adattatori grafici all’interno di un sistema informatico per fornire le massime prestazioni o il minimo assorbimento di potenza dalla grafica del sistema hardware di rendering.
È stato sviluppato per Microsoft e Linux, ma è stato creato un progetto chiamato Bumblebee per un’implementazione open source alternativa del supporto di NVIDIA Optimus per Linux.
Hybrid SLI è il nome generico per due tecnologie, GeForce Boost e HybridPower.
HybridPower è stato in seguito ribattezzato Nvidia Optimus.
GeForce Boost ha permesso di combinare la potenza di rendering di un iGPU e una GPU dedicata per aumentare le prestazioni.
HybridPower è un’altra modalità che non è per il miglioramento delle prestazioni.
Il setup è composto da un iGPU e una GPU sul modulo MXM.
L’iGPU assisterà la GPU per migliorare le prestazioni quando il laptop è collegato a una presa di corrente mentre il modulo MXM si spegnerà quando il laptop sarà scollegato dalla presa di corrente per ridurre il consumo energetico complessivo della grafica.
Funzionamento Hybrid SLI
È disponibile anche su schede madri e PC desktop con schede video dedicate.
Quando un utente avvia un’applicazione, il driver grafico tenta di determinare se l’applicazione trarrebbe vantaggio dalla GPU dedicata.
In tal caso, la GPU viene risvegliata da uno stato di inattività (idle) e le vengono passate tutte le chiamate di rendering.
Anche in questo caso, tuttavia, il processore grafico integrato (iGPU) viene utilizzato per produrre l’immagine finale.
Quando vengono utilizzate applicazioni meno esigenti, l’iGPU assume il controllo esclusivo, consentendo una maggiore durata della batteria e un minore rumore della ventola.
Con Windows, i Driver Nvidia offrono anche la possibilità di selezionare manualmente la GPU nel menu di scelta rapida all’avvio di un’applicazione.
All’interno dello strato di interfaccia hardware del driver delle GPU Nvidia, l’Optimus Routing Layer fornisce una gestione intelligente della grafica.
Optimus Routing Layer include anche una libreria a livello del kernel per il riconoscimento e la gestione di classi e oggetti specifici associati a diversi dispositivi grafici.
Questa innovazione di Nvidia migliora lo stato e la gestione del contesto, allocando le risorse necessarie per ogni driver client (per ogni applicazione ad esempio).
In questo schema di gestione del contesto, ogni applicazione non è a conoscenza delle altre applicazioni che utilizzano contemporaneamente la GPU.
Optimus Routing Layer
Riconoscendo le classi designate, Optimus Routing Layer può aiutare a determinare quando la GPU può essere utilizzata per migliorare le prestazioni di rendering.
In particolare, invia un segnale per accendere la GPU quando trova una di queste 3 tipologie di chiamata:
- Chiamate DX (DX Calls): qualsiasi motore grafico 3D o applicazione DirectX (DX) attiverà questa tipologia di chiamate.
- Chiamate DXVA (DXVA Calls): la riproduzione video attiverà questa tipologia di chiamate (DXVA acronimo per DirectX Video Acceleration).
- Chiamate CUDA (CUDA Calls): le applicazioni CUDA attiveranno questa tipologia di chiamate.
I profili predefiniti aiutano anche a determinare se è necessaria una potenza grafica aggiuntiva.
Questi possono essere gestiti utilizzando il pannello di controllo Nvidia.
Optimus evita l’uso di un multiplexer hardware (una specie di combinatore di segnali) e previene i glitch (malfunzionamenti) associati alla modifica del driver da iGPU a GPU dedicata, trasferendo la superficie dello schermo dal framebuffer della GPU dedicata, tramite il bus PCI Express, al framebuffer basato sulla memoria principale utilizzato dall’iGPU.
Optimus Copy Engine è una nuova alternativa ai tradizionali trasferimenti DMA (acronimo per Direct Memory Access, un accesso alla memoria principale senza passare per la CPU) tra la memoria del framebuffer GPU e la memoria principale utilizzata da iGPU.
AMD Hybrid CrossFire/CrossFireX/Dual Graphics
È la controparte AMD dell’Hybrid SLI, il funzionamento è circa lo stesso, con 3 modalità di funzionamento:
- Solo iGPU
- Solo GPU dedicata
- Ibrido tra iGPU e GPU dedicata
Hybrid CrossFireX è una tecnologia che consente all’iGPU e alla GPU dedicata di creare una configurazione CrossFire per migliorare la capacità del sistema di rendering di scene 3D.
La tecnologia Hybrid CrossFire X è presente sul primo chipset 790GX e 890G, con due slot fisici PCI-E x16 in dotazione con bandwidth x8, possono formare una configurazione ibrida di CrossFire X con due schede video e iGPU, migliorando le funzionalità di rendering 3D.
Il SurroundView è il termine usato per controllare più monitor in extended desktop mode o in clone/mirror/duplicate mode.
L’iGPU e la GPU dedicata funzionano in parallelo per pilotare display multipli.
Il successore di SurroundView è AMD Eyefinity (nota anche come DCE acronimo di display controller engine).
Il PowerXpress consente il passaggio senza interruzioni dalla grafica integrata (iGPU) alla grafica dedicata su notebook quando il notebook è collegato all’alimentazione per migliorare le funzionalità di rendering 3D e viceversa quando scollegato dall’alimentazione elettrica per aumentare la durata della batteria.
Il processo non richiede il riavvio del sistema come nel passato e alcune implementazioni correnti di notebook.
Memoria Video nel mGPU
Sulle schede Video AMD e NVIDIA in multi-GPU (qualsiasi scheda in SLI o CrossFireX) con qualsiasi libreria sia in DX11, che in DX12, che in Vulkan etc. la VRAM è solo copiata, in quanto ognuna renderizza un’immagine che occupa nello stesso momento un peso uguale su entrambe le memorie.
L’utilizzo di DX12 / Vulkan non cambia la situazione in queste schede per un’impossibilità dovuta al tipo di connessione Master-Slave.
Schede Video NVIDIA in NVLink possono usare entrambi le memorie video per differenti scopi rappresentando quindi non un’effettiva condivisione, ma una somma di memoria 6GB+6GB (non significa che diventino 12GB).
Questo può avvenire solo in DX12 e Vulkan, mentre non succede in DX11 neanche utilizzando NVLink.
concetto memoria condivisa, memoria sommata, memoria copiata
Per memoria condivisa, si intende che, se io ho un unico grandissimo e unico file grande 7GB, posso tranquillamente utilizzare 6GB di una scheda e 1GB della restante scheda, in quanto la scheda accede e condivide con l’altra scheda la memoria come se fossero un tutt’uno.
Questo non può avvenire poiché causerebbe un enorme aumento della latenza tra le GPU, dovendo accedere alla memoria dell’altra scheda come memoria aggiuntiva ma più distante.
Per memoria sommata si intende che la memoria si divide in due blocchi, se ho 6 file grandi 2 GB l’uno, posso tranquillamente fare 3 file da 2GB su di una scheda occupando 6GB e 3 file da 2GB sull’altra scheda occupando altri 6GB.
Se ho 1 file da 6GB occuperò in totale 6GB dei 6GB+6GB.
La memoria copiata significa che se io ho 1 file da 6GB sulla prima scheda, questo file deve copiato uguale sulla scheda Slave occupando 6GB e saturando anche la sua memoria video quindi occuperò 12GB dei 6GB+6GB con un solo file da 6GB.
Linee PCI-E x16, x8 e x4
Breve video di R3D3X alias Tech qp, l’autore di questa immensa guida, chi non lascia un like sul suo canale avrà notti insonni.
Scherzi a parte, supportate l’ENORME lavoro di un nostro connazionale!
Vantaggi e Svantaggi del multi-GPU
Vantaggi mGPU:
- Maggiori Prestazioni.
- Potenziare il PC senza dover vendere la scheda video.
- Combo di schede con un ottimo rapporto qualità/prezzo possono superare schede più costose.
- Combo di schede top di gamma creano più potenza della singola scheda più potente esistente.
(Esempio: due GTX 980 Ti, due GTX 1080 Ti o due RTX 2080 Ti)
Svantaggi mGPU:
- Molte CPU attuali non supportano due schede in PCIe x16 + PCIe x16, più spesso le vediamo in PCIe x8 + PCIe x8, se non c’è un NVMe a prendersi 4 linee o se si possiede Ryzen che riserva 4 linee per gli NVMe, altrimenti potremmo avere le schede video in PCIe x8 + PCIe x4 e l’NVMe in PCIe x4.
- Maggiori Consumi.
- Spesa per PSU maggiorato (750W/850W in su, dipende dalle due GPU).
- Spesa per il Bridge.
- Maggiore Calore, sopratutto se poste una sopra l’altra e non distanziate da almeno uno slot.
- Alcuni giochi non supportano SLI/CF, quindi userete una sola scheda video.
- Molti giochi non sono ottimizzati per lo SLI.
- Limitazioni varie per GPU “diverse”, dipende se usate SLI o CF.
- Le Prestazioni non sono il doppio quindi il 100% in più, ma in genere un 20-50% in più rispetto ad una scheda video (spesso di meno, in altri casi di più).
In determinati casi il gioco non vale la candela conviene di più sostituire la scheda e vendere la vecchia.
Produzione Wafer
Eccovi due video in cui spiegano approfonditamente i vari passaggi della produzione:
Nella foto sottostante vediamo i Wafer di silicio con una struttura cristallina regolare, e con il silicio avente una struttura cubica diamantata con una spaziatura reticolare di 0.543 nm.
Sono Wafer purissimi al 99,9999999%, le impurità in genere sono volute tramite il drogaggio del silicio con concentrazioni tra 10¹³ e 10 ¹⁶ atomi per cm³ di boro, fosforo, arsenico e antimonio.
Vengono aggiunti al fuso tramite la Ion Implantation e definiscono (in base ai materiali usati per il drogaggio) se il wafer è di tipo-n (fori con carica negativa) o di tipo-p (fori con carica positiva).
Le restanti impurità sono ridotte al minimo possibile tramite vari filtri e un’asetticità elevata se non totale.

Processo di Czocharalski
La quarzite grezza viene raffinata fino a diventare silicio policristallino, di grado elettronico (EGS), ovvero silicio con meno di un’impurità ogni miliardo di atomi.
Il polisilicio di tipo EGS viene sottoposto ad accrescimento cristallino per ottenere un lingotto cilindrico monocristallino ultrapuro chiamato boule tramite una delle due tecniche, o tramite il processo di Czocharalski (CZ) o tramite la Float Zone (FZ).

Ogni lingotto viene segato tramite una sega a filo (sega wafer), in modo da ottenere i wafer citati prima e lappato.
In questo modo si evita che sulla superficie del wafer vi siano irregolarità che si possano ripercuotere in maniera pesante sul buon funzionamento del circuito integrato.
A causa delle irregolarità si potrebbero avere variazioni dello spessore delle piste conduttrici, con conseguenti variazioni, in qualche punto, della conducibilità elettrica delle stesse.
Una volta realizzati i wafer, la cui parte inferiore è definita bulk (massa), questi hanno un diametro di 10-12 pollici e con uno spessore inferiore al millimetro.
Lavorazione
La parte superiore sarà quella lavorata, ovvero sulla superficie del wafer.
Successivamente la realizzazione è necessario proteggerlo da processi corrosivi (come l’acqua nell’aria) tramite un materiale isolante, ovvero l’ossido di silicio (SiO2).
Quest’ultimo impedirà cortocircuiti tra le piste conduttrici disposte su layer (livelli) diversi.
Il materiale viene depositato sul wafer, e viene esposto ad agenti ossidanti quali aria e acqua, ad alte temperature oltre i 1000°, altrimenti si formerebbe del quarzo.
Costringendo l’ossido ad avere una crescita termica sulla fetta di silicio, infatti, si fa in modo che esso si deformi non costituendo più una struttura cristallina, ma amorfa.
L’ossido di silicio viene quindi usato per la passivazione (impedisce la corrosione dei metalli) mentre per proteggerlo dall’umidità si utilizza il nitruro di silicio (Si3N4).
Questi strati isolanti vengono di solito deposti per sputtering (vaporizzazione catodica) o chemical vapor deposition (CVD).
Fotoresist di Tipo-P e di Tipo-N

La fabbricazione dei circuiti integrati sui wafer di silicio richiede che molti layer, ognuno con uno schema diverso, siano depositati sulla superficie uno alla volta, e che il drogaggio delle zone attive venga fatto nelle giuste dosi evitando che esso diffonda in regioni diverse da quelle di progetto.
I vari pattern usati nella deposizione dei layer sul substrato sono realizzati grazie ad un processo chiamato litografia.
Durante la litografia, i wafer vengono rivestiti di un materiale chiamato photoresist (PR), e selettivamente esposto a radiazioni luminose (fotolitografia).
Quindi la radiazione luminosa attraversa una maschera sulla quale è stato precedentemente realizzato il pattern che si vuole conferire al layer sul substrato di silicio, e che è trasparente ovunque tranne nelle zone sulle quali sono state realizzate le forme dello schema.
Quando il photoresist viene bombardato da un’opportuna radiazione, esso si polimerizza.
Dopo l’esposizione il PR è soggetto a sviluppo (come una pellicola fotografica) che distrugge le zone esposte alla radiazione o quelle in ombra a seconda che si sia usato un PR positivo (type-p) o negativo (type-n).
Viene rimosso il photoresist in eccesso tramite etching o lift-off (in base alla tipologia, se p o n), cercando di ridurre al minimo i possibili danni alla parte sottostante.
L’ultimo passo è l’hard banking, necessario per indurire il photoresist e migliorarne l’adesione alla superficie del wafer.
Segue poi la fase del taglio nei singoli dice.
Ci riferiamo spesso al die anche come Integrated Circuit Die (il cui acronimo è ICD, o IC, traducibile come Circuito Integrato Stampato), il plurale della parola inglese die ha tre possibili forme: dice, dies e die.
Il die messo a nudo

Lo sfaldamento del wafer, si verifica in genere solo in alcune direzioni ben definite.
I die sono allineati in una delle varie direzioni note come Crystal Orientations; l’orientamento è definito dall’indice Miller con 100 o 111 facce che sono le più comuni per il silicio.
Il calcolo del wafer lungo i piani di clivaggio consente di suddividerlo facilmente in singoli dice (stampi) in modo che i miliardi di singoli elementi del circuito su un wafer medio possano essere separati in molti circuiti singoli identici l’uno all’altro.
A questo punto vengono eseguiti i Wafer Test e tutti i chip vengono controllati, e si definisce resa, il rapporto tra il numero di dice funzionanti e quello di dice totali prodotti.
Tale valore nelle moderne fabbriche è anche superiore al 90% in base allo sviluppo del processo produttivo a quei determinati nanometri.
IHS (Integrated Heat Spreader)

Questi dice vengono poi applicati all’interno di contenitori detti chip carrier (tradotto come porta-chip o anche detto PlCC, acronimo di Plastic Leaded Chip Carrier) che rappresenta una parte del package (infatti il processo di chiusura e imballaggio, è detto die-packing) e collegati ai terminali metallici del package con filo metallico (processo di wire bonding).
I terminali del package sono il tramite con cui il die può comunicare con il circuito in cui verrà inserito.
Il pezzo di metallo che chiude il chip carrier viene chiamato IHS (acronimo di Integrated Heat Spreader), unito al Die tramite il TIM (acronimo di Thermal Interface Material) che rappresenta la pasta termica che fa passare il calore dal die all’IHS.
Al di sopra dell’IHS verrà poi posta la pasta termica o un pad termico che servirà a condurre il calore dal package della GPU all’Heatsink della scheda video.
Il Delid è l’apertura del package, in genere con l’obiettivo di rimuovere la pasta termica prodotta dalla fabbrica per cambiarla con una pasta termica più efficiente in genere Metallo Liquido.
Questa procedura è molto rischiosa, ma garantisce in genere, se fatta correttamente, migliori temperature, a volte anche di parecchi gradi.
Binning, Rebrand e Nomi in Codice
NVIDIA e AMD sono i due più famosi produttori di schede video dedicate, ma ciò che loro fanno è solo il design del die oltre definire le varie specifiche delle schede video
Per questo sono definiti come aziende Fabless, ovvero svolgono il ruolo di progettazione e vendita ma la fabbricazione è affidata a ditte esterne definite come fab (per l’appunto fab-less, senza fabbrica).
Queste fonderie di semiconduttori in genere sono in Cina o a Taiwan, in questo modo risparmiano sui costi di adeguamento delle strutture, utilizzando i guadagni in ricerca e sviluppo, guardando poi verso il mercato finale.
La vera produzione delle GPU è quindi affidata alle fab, e tra le più famose annoveriamo TSMC (Taiwan Semiconductor Manufacotory Company, al 1° posto tra le più grandi al mondo).
A seguire vi è la WaferTech (sussidiaria controllata interamente ormai da TSMC), la GlobalFoundries (al 2° posto tra le più grandi al mondo) e UMC (3° in tutto il mondo).
Le Fab sono definite dal diametro dei wafer che producono da 1-inch (25,4mm) a 16,7-inch (450mm), mentre i valori sono in continuo cambiamento e possono variare.
Non tutte le GPU prodotte sono uguali.
A causa proprio del processo di costruzione molto lungo e complesso, può quindi capitare che chip usciti dalla stessa linea di produzione siano leggermente diversi.
Un aspetto che viene tecnicamente definito Binning ovvero la classificazione dei prodotti in base alle loro caratteristiche, secondo il quale vengono categorizzati i chip, teoricamente identici, che escono da una linea di produzione in base alle loro performance termiche e di frequenza.
Binning
Le GPU con un binning più alto sono solitamente quelle capaci di operare a una frequenza di clock maggiore, rispetto a quelle con un binning più basso.
Le specifiche di base sono pensate secondo un minimo comune denominatore e alcuni assemblatori terzi, come Gigabyte per esempio, possono assicurarsi lotti delle GPU migliori per creare schede come GTX 1080Ti di diverse fasce:
1) Aorus GeForce GTX 1080 TI Extreme (Gigabyte) – Boost: 1746 MHz / Base: 1632 MHz in OC mode o in Gaming mode Boost: 1721 MHz / Base: 1607 MHz
2) Aorus GeForce GTX 1080 TI (Gigabyte) – Boost: 1708 MHz / Base: 1594 MHz in OC mode o in Gaming mode Boost: 1683 MHz / Base: 1569 MHz
3) GeForce GTX 1080 TI Gaming OC (Gigabyte) – Boost: 1657 MHz / Base: 1544 MHz in OC mode o in Gaming mode Boost: 1632 MHz / Base: 1518 MHz
4) GeForce GTX 1080 TI Founder Edition (Gigabyte) – Boost: 1582 MHz / Base: 1480 MHz
In ordine la prima ha teoricamente un binning più alto rispetto alle altre, poi la seconda, poi la terza e infine come binning più basso abbiamo la quarta.
GPU più efficienti
Naturalmente, il numero di queste GPU super efficienti è limitato in ognuno dei lotti di produzione, quindi gli assemblatori di schede video sono sempre disposti a pagare di più rispetto al prezzo base per potersele assicurare, quindi piazzano un ulteriore rincaro nella vendita di queste particolari schede video.
Queste varianti implicano un livello di binning diverso e una crescente “raffinatezza” nel processo produttivo. C’è da dire che stesse varianti dello stesso chip binned possono avere un binning diverso, ovvero un chip può essere definito “più fortunato” rispetto ad un altro poiché durante la fase di overclock a parità di voltaggi, frequenze e dissipazione; riesce a mantenere stabilmente frequenze più alte rispetto ad una sua stessa variante.
Il binning implica che moltissime GPU non riescono a raggiungere le performance minime richieste, questo a causa della complessità delle procedure di costruzione dei chip.
È normale che da questa grande produzione, un grande numero di chip sia da scartare.
Non tutti questi scarti sono da buttare però.
Alcuni non sono difettosi come altri, e disabilitando alcune delle parti problematiche, o riducendo la frequenza operativa, si riesce comunque a realizzare una scheda video, anche se incapace di fornire le prestazioni di quelle pienamente riuscite.
Questo è il motivo che rende interessanti schede basate sulle GTX 1070: la 1070 in partenza era una 1080 non inutilizzabile, poiché non riusciva a raggiungere le prestazioni di riferimento previste.
In questi casi, AMD e NVIDIA possono comunque utilizzare il chip prodotto, e i consumatori beneficiarne ugualmente, visto che possono acquistare schede video dalle funzionalità ridotte, ma sempre molto interessanti, a prezzi di molto inferiori.
Rebrand
Gli scarti ottenuti dalla produzione di una GPU nuova sono sostanzialmente più alti rispetto a quelli ottenuti da un chip di qualche anno prima.
Ciò è dovuto all’affinamento del processo di produzione dei chip.
Le intere serie Radeon R9 2xx e R9 3xx esistono perché l’alta efficienza produttiva consentiva ad AMD di tagliare i prezzi.
Così facendo reintrodusse quelli che erano i suoi prodotti di punta su un mercato di fascia media.
Il processo di Rebrand, molto usato da AMD, come nel caso della serie Polaris RX 4xx, ha permesso di ottenere il passaggio alla serie RX 5xx.
Nel periodo di uscita il fenomeno del mining colpì duramente i prezzi delle schede video AMD e in parte di quelle NVIDIA.
Quando i prezzi delle schede di fascia mainstream, ovvero RX 580 8GB e delle 1060 6GB, si normalizzarono, quelli delle RX 580 subirono una brusca discesa.
Ciò avvenne in quanto l’alta efficienza produttiva consentiva di tagliare i prezzi che fino a quel momento furono alterati dal fenomeno del mining.
Altre tipologie di schede video
Ogni GPU ha un nome diverso da quello delle schede video.
Prendiamo per esempio le GPU NVIDIA della serie 10XX, in questo caso il numero più basso indica il chip più potente nelle prime 3 cifre, mentre la seconda parte indica la variante dello stesso chip dal più potente (numero più alto) al più debole (numero più basso).
Esempio pratico: GP100 (Quadro GP100), GP102-450 (Titan Xp) GP102-400 (Titan X Pascal), GP102-350 (GTX 1080 Ti), GP104-400 (GTX 1080), GP104-300 (GTX 1070 Ti), GP104-200 (GTX 1070), GP106-400 (GTX 1060 6GB), GP106-300 (GTX 1060 3GB), GP107-400 (GTX 1050 Ti), GP107-300 (GTX 1050).
Come si può notare Titan Xp, Titan X Pascal e GTX 1080 Ti condividono la medesima GPU102 ma con qualche differenza interna che ne crea le GPU Variant (-450, -400, -350).
Allo stesso modo GTX 1080, GTX 1070Ti e GTX 1070 condividono il medesimo chip, GP104, ma con differenze interne, le ultime 3 cifre servono appunto per differenziare queste varianti (-400, -300, -200).
Quindi tutto questo si conclude dicendo che una Titan Xp ha come sigla completa della sua GPU, GP102-450-A1.
GPU Revision
Per l’appunto la sigla A1 che ritroviamo alla fine è la dicitura della GPU Revision, ovvero il numero di eventuali revisioni fatte alla GPU.
La sigla GP specifica l’architettura della GPU ovvero in questo caso l’architettura NVIDIA Pascal.
Nel caso dell’architettura NVIDIA Maxwell troviamo la sigla GM o precedente ancora a Maxwell l’architettura NVIDIA Kepler ovvero la sigla GK.
Nella serie GPU 20XX la sigla TU indica l’architettura NVIDIA Turing, questo poiché NVIDIA in genere utilizza nomi di famosi matematici e fisici.
Attualmente sia AMD che NVIDIA si rivolgono a TSMC o a Global Foundry (definiti appunto come Foundry) per la produzione delle loro GPU.
La maggior parte sono prodotte da TSMC, ma anche Global Foundry fa del suo ad esempio con le Vega 56 e 64 (ricordatevi che GF è sempre un’acquisizione delle vecchie fonderie di AMD).










